RepoSwarm: Give AI Agents Context Across All Your Repos

TLDR;
Go see it here.
Intro
Let's say you have 400+ repositories in your company. And you're:
- A software architect that needs to understand what monitoring tools are used across all the repositories, and you want to ask an AI chat to help you
- A Security researcher that needs to understand which 3rd party vendors we're working with for HIPAA compliance, and you want to ask an AI agent to help you
- A developer working on a new feature that depends on multiple services across multiple repositories, and you want to understand if you're using them correctly, or their contracts, and you want to ask an AI agent to help you.
- An AI coding agent trying to generate a new feature and needing as context multiple repositories and their structure, how they're built and contracts
- An AI agent trying to reason about and generate a list of compliance or security or other reports that span multiple repositories
Along with a couple of friends from work, we created RepoSwarm.
RepoSwarm is an AI powered multi-repo architecture discovery platform that generates its output in a specialized output repository that you can use for agent context.
Its purpose is to create context for AI agents to better help with reasoning about very complex multi-repo organizations (hundreds of repositories) and describe dependencies, security issues, architecture, tooling, monitoring, AI and ML workloads, infrastructure and any other thing we can ask as a prompt.
To accomplish this, RepoSwarm uses a series of workflows using the temporal workflow engine.
The Problem with Architecture "Documentation"
If you're like me and most companies I've ever worked with, your architecture documentation is either:
- Six months out of date
- Scattered across 17 different wiki pages
- Living entirely in Bob's head (and Bob left the company)
- All of the above
Also, it's not fit for AI agent consumption.
The Problem Nobody Has Time to Fix
What if your repositories could document themselves, continuously, intelligently?
Enter RepoSwarm.
RepoSwarm is an open-source project that:
- Crawls your GitHub (private and public) repositories daily in search of changes
- Analyzes them using Claude Code SDK (you can control which model)
- Generates standardized architecture documentation in the form of a markdown file per repo.
- Stores it all in a searchable format
- Runs forever until you tell it to stop
- You can configure it to run any series of investigations on repos you wish , and it will only run them when there are new commits, or a new investigation type is added or changed.
That's it. No magic. No "revolutionary paradigm shifts." Just a practical solution to a real problem.
How It Works
The system is built on Temporal - if you haven't used Temporal yet, think of it as something like N8N (but code-first) or airflow, but usually used for production workflows. Temporal orchestrates workflows in a code-first manner (no visual designer). Workflows can run for hours, days, or indefinitely without losing state.
Here's what it looks when you run it locally and go to the local temporal server on your machine:
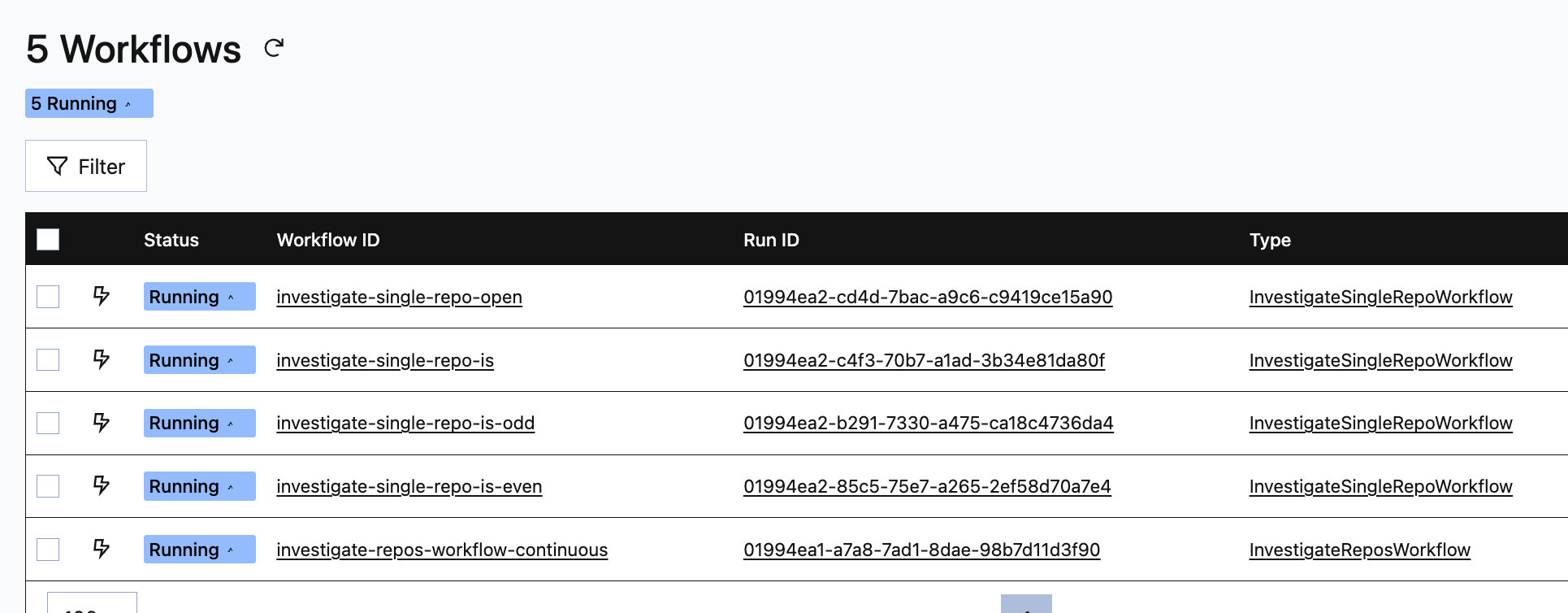
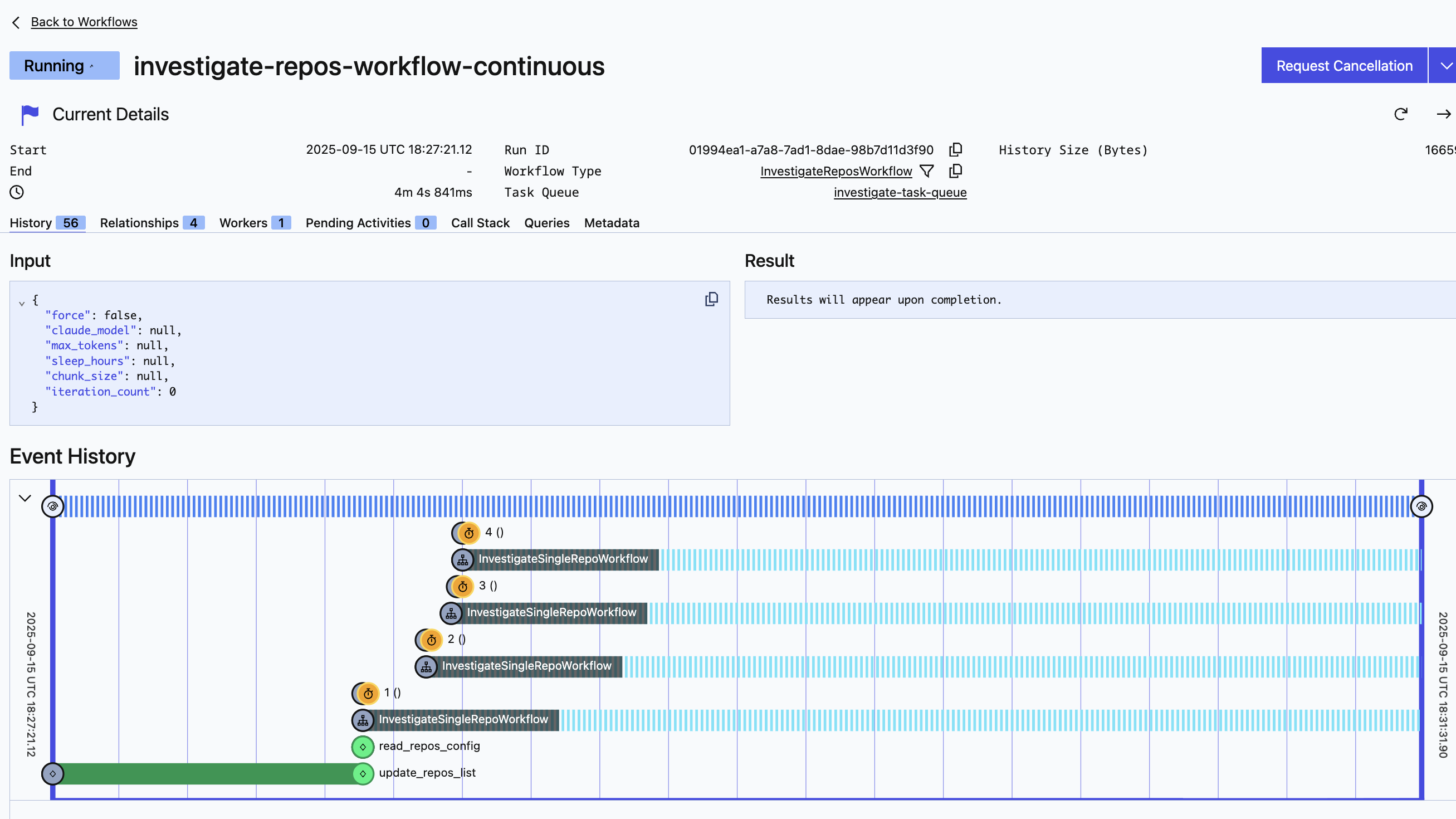
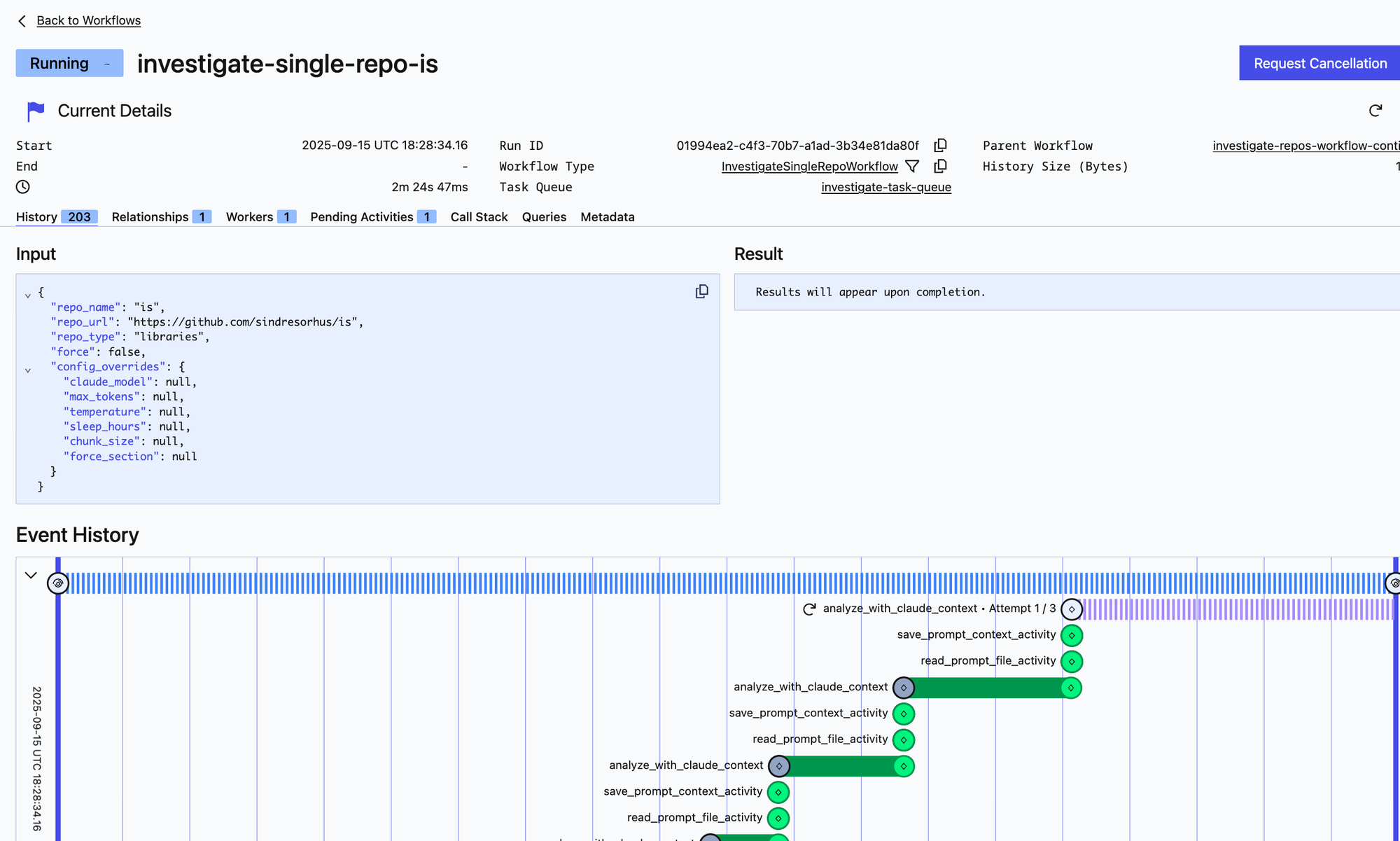
RepoSwarm flow is straightforward:
- Discovery Phase: RepoSwarm looks at your repos.json and also queries GitHub for all the private and public github repos under your organization or account. It auto-selects only repos that have at least one commit in the past 12 months.
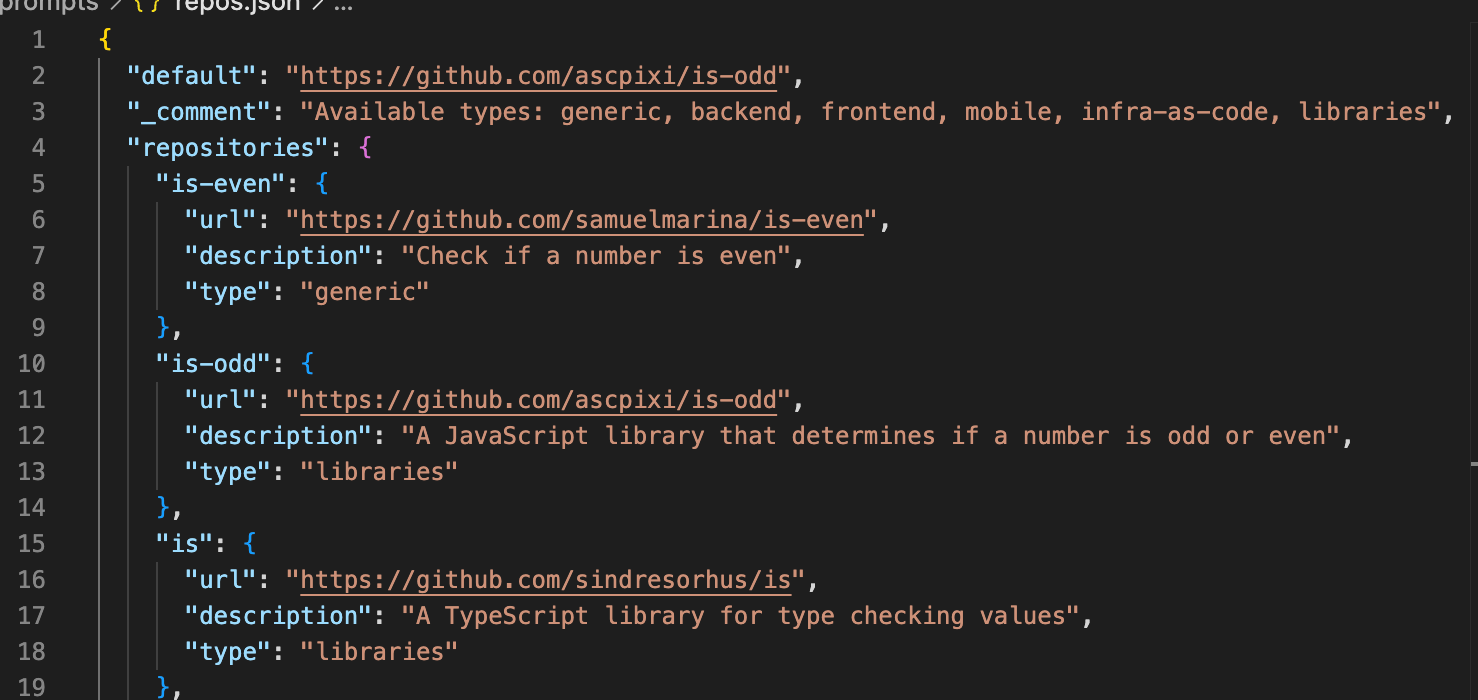
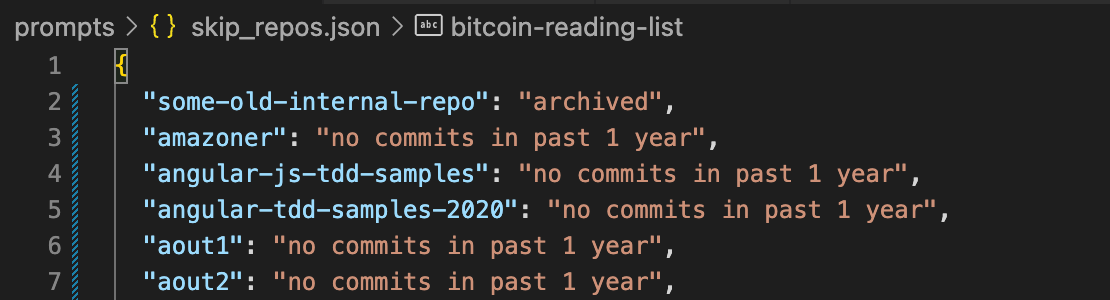
- Skipping Phase: Skipped repos are marked in skipped_repos.json and will be comprised of:
- auto-skipped repos due to no activity in past 12 months)
- auto-skipped repos due to being archived
- repos you explicitly tell RepoSwarm to skip (you can put any comment you want):
- Smart Analysis: in repos.json, you can set a "type" for a repo, so it gets extra investigations. for example, mobile repos will get more investigations relating to mobile specific architecture questions, and infrastructure as code repos will get infra related arch investigations. A React app doesn't need the same questions as a Kubernetes config repo.
- Prompt Result Caching: Already analyzed this repo? Same commit? Same Prompts? Skip it.
We're not wasting tokens. RepoSwarm keeps state snapshot pairs for each commit+(prompt+prompt-version) pairs, so if there is a new commit, all prompts will run against that repo, but if there's a new prompt, or a new prompt version, only that new prompt will execute against that repo, and all other investigations will be skipped , returning the cached result from previous run.
Caching can use DynamoDB or (when running locally) local file system /temp directory. - Prompt Versioning: Prompt files contain the prompt version as the first line as a barbaric but effective mechanism to trigger new investigations for that prompt, and avoiding creating a dependency on specific tools like LangFuse.
- Documentation Generation: Creates
repo-name.arch.mdfiles and commits them to a [target-repo] that you specify.
Adding new prompts
add a new prompt either under prompts/shared or prompts/specialized-folder-name, then add the new prompt to base_prompts.json or the /prompts/specialize-folder-name/prompts.json
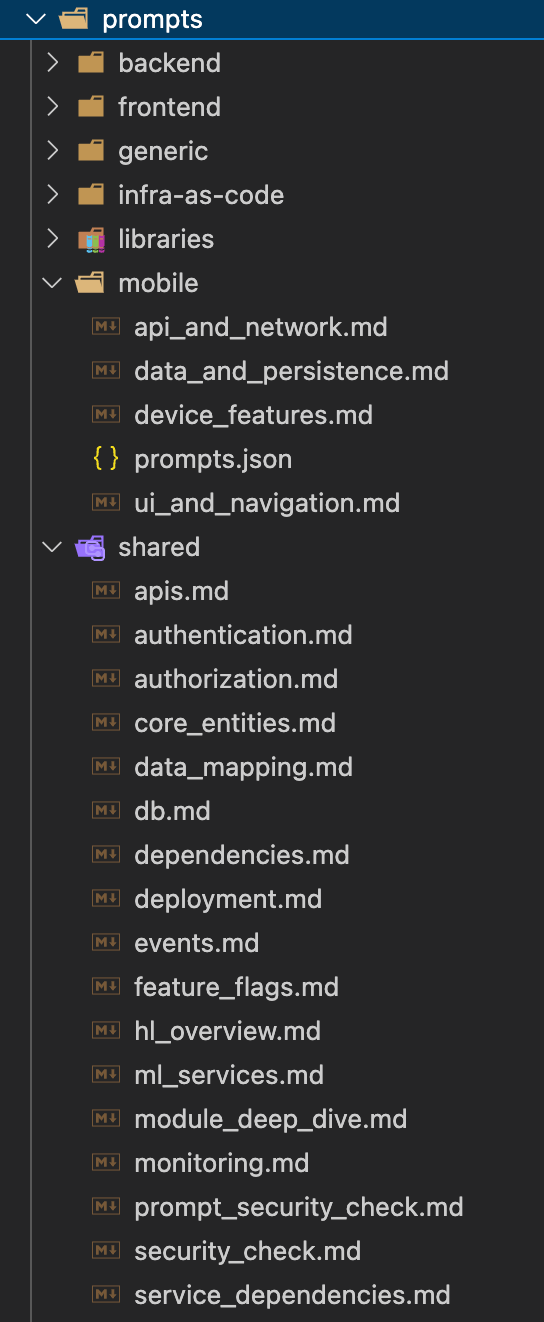
All repos will be analyzed by all prompts in base_prompts, followed by any specialized prompts if their repo_type is named under one of the prompts/folder like "mobile" or "libraries".
Example: base_prompts
{
"processing_order": [
{
"name": "hl_overview",
"file": "../shared/hl_overview.md",
"description": "High level overview of the codebase"
},
{
"name": "module_deep_dive",
"file": "../shared/module_deep_dive.md",
"description": "Deep dive into modules",
"context": [
{"type": "step", "val": "hl_overview"}
]
},
{
"name": "dependencies",
"file": "../shared/dependencies.md",
"description": "Analyze dependencies and external libraries",
"context": [
{"type": "step", "val": "hl_overview"}
]
},
{
"name": "ml_services",
"file": "../shared/ml_services.md",
"description": "3rd party ML services and technologies analysis",
"context": [
{"type": "step", "val": "hl_overview"}
]
},
{
"name": "feature_flags",
"file": "../shared/feature_flags.md",
"description": "Feature flag frameworks and usage patterns analysis",
"context": [
{"type": "step", "val": "hl_overview"}
]
},
{
"name": "prompt_security_check",
"file": "../shared/prompt_security_check.md",
"description": "LLM and prompt injection vulnerability assessment",
"context": [
{"type": "step", "val": "hl_overview"},
{"type": "step", "val": "ml_services"}
]
}
]
}
Notice how we can actually inject the output of other investigation prompt results into the context of other prompts (see prompt_security_check.context array).
Example: mobile prompts
And here's a mobile specific set of prompts, that will run for any repo in repos.json marked as "mobile" type, on top of everything in base_prompts.json.
/prompts/mobile/prompts.json
{
"extends": "../base_prompts.json",
"additional_prompts": [
{
"name": "ui_and_navigation",
"file": "ui_and_navigation.md",
"description": "UI architecture and navigation patterns"
},
{
"name": "api_and_network",
"file": "api_and_network.md",
"description": "API integration and network communication"
},
{
"name": "device_features",
"file": "device_features.md",
"description": "Native device features and capabilities"
},
{
"name": "data_and_persistence",
"file": "data_and_persistence.md",
"description": "Data persistence and state management"
}
]
}Output: The Architecture Hub Repo
All the generated documentation goes to a central repository that you decide on. Think of it as your architecture wiki that updates itself. The companion project repo-swarm-sample-results-hub shows how this works.
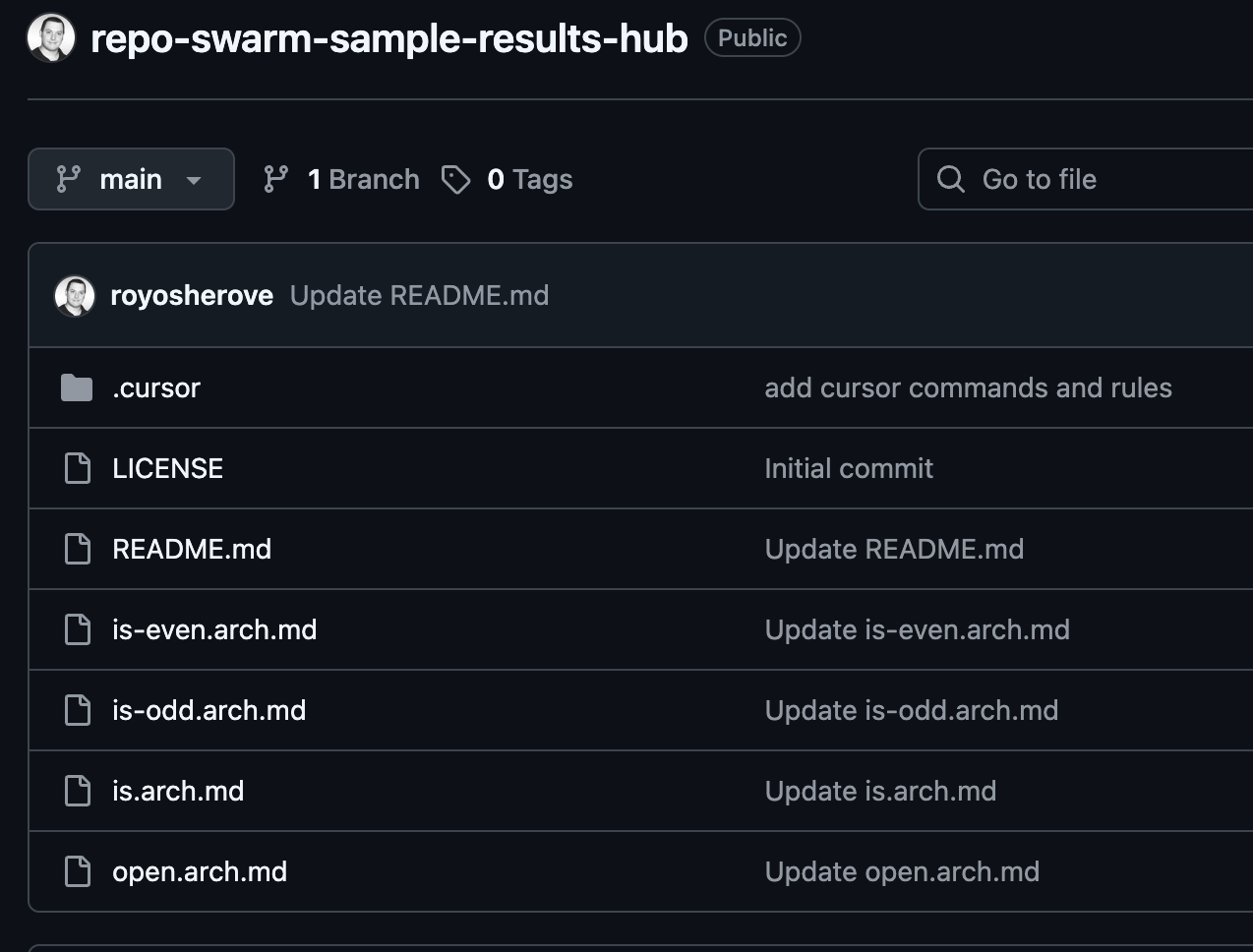
You can query it, search it, or just browse it like any other repository. Except this one is always up to date.
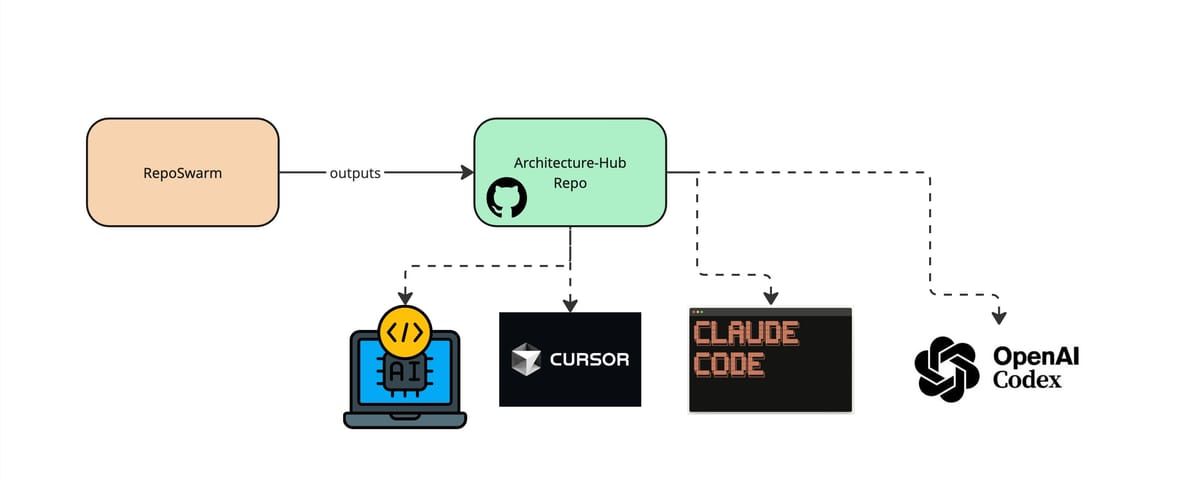
Using RepoSwarm Output as Agent Context
As a first step, I like to attach the output repo into my cursor workspace as an added project, and ask it questions or give it as context to the coding agent as I plan complicated features in the chat.
Future plans include:
- Adding a Repo-bot in slack with backing RAG based on the output repo
- Add the context into Cursor, Claude and Codex agents automatically
- Exposing an MCP to the Repo as a simple context scanning tool
- Creating deeper investigations as RepoSwarm works so that it can "jump" and investigate related repos while investigating a specific repo, to get even more context.
- more?
Real-World Use Cases
- Onboarding New Developers to all our repositories
- Architecture Reviews
- Compliance Audits
- Knowledge Transfer
- Providing extra context to coding agents or as an MCP server related to architecture
What This Is NOT
- It's not a code generator
- It won't fix your architecture (just document it)
- It's not a replacement for human insight
Contributing
The project is open-source (Apache-2).
Contributions are welcome.
Areas that need help:
- Additional analysis prompts
- Integration with other AI providers (right now using claude code SDK because the tooling flow just works)
- Performance optimizations